中国网/中国发展门户网讯 随着深度学习等技术近年来的突破,人工智能(AI)在数学、物理学、化学、生物学、材料学、制药等自然科学和高技术领域的研究中得到了广泛应用。例如,DeepMind利用机器学习方法辅助发现数学猜想和定理证明;生物学领域中AlphaFold2已经可以预测超过350 000种人类基因组蛋白质,以及超过100万个物种的2.14亿个蛋白质,几乎涵盖了地球上所有已知的蛋白质,解决了困扰结构生物学50年的难题;DeepMind和瑞士等离子体中心合作提出将强化包養学习用于优化托卡马克内部的核聚变等离子体控制;华盛顿大学戴维·贝克教授团队利用AI技术精准地从头设计出能够穿过细胞膜的大环多肽分子,创新了口服药物设计的新思路。这一系列人工智能技术的成功应用都标志着以AI for Science(智能化科研)为核心的第五科研范式已经成为提升科研效率,推进科学发现和科技创新的强大工具,有望带来人类社会的重大变革。
虽然AI for Science应用领域非常广泛,但在不同学科领域的应用又有所差别。笔者认为可以将其进一步细分为广义和狭义的AI for Science。其中,广义的AI for Science是多种人工智能技术在科学技术领域的广泛应用,既包括了自然科学领域的规律和知识发现(如数学猜想的证明、物理规律的发现等),也涵盖了解决高技术领域的关键技术难题(如超短临天气预报、托卡马克控制、生物制药等)。狭义的AI for Science重点强调自然科学领域的内在规律、知识和结构发现,如发现行星运动的开普勒定律、发现人类基因组蛋白质结构等。与狭义的AI for Science不同,AI用于解决高技术领域的关键技术难题主要依赖于发明和创造出新的人造物(artifacts),包括新方案、新方法、新工具和新产品等。AI在高技术领域的应用,由于其应用目的、技术路线等方面和狭义的AI for Science有所不同,笔者认为更适合将其归类到AI for Technology(技术智能)的范畴。
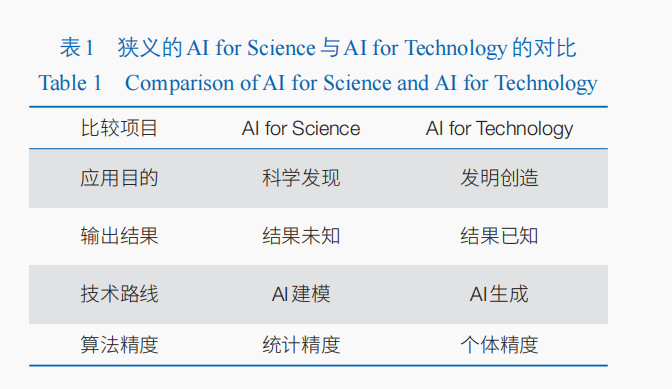
表1总结了狭义的AI for Science和AI for Technology的区别。从应用目的来看,如前所述,AI for Science目的是希望发现自然科学领域人类目前未知的运行机制、机理、规律、结构等;而AI for Technology更强调的是发明创造出满足特定需求的方案、方法、工具和物品等。以信息论来进行类比,AI for Science可以看作是信息编码和压缩的过程,通过AI将大量观察数据编码成符号化的规律或知识;AI for Technology可以看作是信息解码和解压缩的过程,通过AI将大量满足需求规范的样例解码成人造物的具体设计细节和组成成分。从输出结果来看,AI for Science本身具有强烈的探索性,其输出结果是事先未知的;AI for Technology是设计出符合预定义需求规范的人造物,其输出结果是精确已知的。从技术路线来看,AI for Science主要利用了AI的强大建模能力,实现对大量观察数据的准确拟合;而AI for Technology则更侧重于利用AI的生成能力,以生成满足需求规范的目标人造物。从算法精度要求上看,AI for Science追求的是大量数据下统计意义的可接受性,要求输出的结果可以合理地解释自然现象(输入数据),如输入数据符合特定的统计分布规律;而AI for Technology强调的是单个个体的精确,要求输出的个体结果能够精确地满足预定义需求规范,如计算机程序自动设计要求输出的程序代码能够正确满足功能和性能规范。从这个角度看,AI for Technology对AI算法提出了更高的精度要求。
实际上,有关AI for Technology的研究自AI诞生以来就一直备受关注。1969年,诺贝尔经济学奖及图灵奖获得者、人工智能的奠基人之一赫伯特·西蒙(Herbet Simon)在其《人工科学》(The Sciences of the Artificial)一书中包養網对“自然物”和“人造物”进行了区分,并明确了发明创造满足人类需求的人造物本身也是门科学(artificial science),可以通过基于计算机程序的通用问题求解系统(general problem solver)来建模人类解决问题的流程,以实现“无人干预的设计”。赫伯特·西蒙和另一位人工智能的奠基人艾伦·纽威尔(Allen Newell)实现了通用问题求解系统,以自动解决多种不同类型的问题。这本质上是把人类求解问题的过程建模成由机器自动完成的搜索过程。其中的重要组成部分是“生成器—测试”(Generator-Test)的循环,即通过生成器产生大量的潜在候选,然后通过测试来确定候选是否满足需求规范,反复迭代直到找到满足需求的候选。
参考上述流程,可以将AI for Technology建模成为“搜索+验证”的流程。“搜索+验证”流程的核心是通过搜索算法挑选合适的候选,自动验证所挑选的候选是否满足需求规范,如果不满足则需要自动修改和调整以生成新的候选,直到最终的输出结果满足需求。近年来,随着AI技术的快速演进,有望同时提升上述搜索和验证的效率,在扩大应用领域的同时加速整个问题求解的流程。
AI for Technology的科学问题及关键挑战
实现AI for Technology中“搜索+验证”的循环迭代,本质上是要解包養網比較决如何在庞大的高维空间中找到精确满足复杂约束的最优解问题。对于实际的工程技术问题,其待搜索空间通常包含海量的潜在候选。以围棋为例,棋盘有361个位置,而每个位置有3种可能,其状态空间为3361;以蛋白质设计为例,长度为200的氨基酸蛋白,其可能序列有20200种可能;以软件程序设计为例,长度仅为100条指令的小程序(以广为使用的SPEC CPU程序为例,实际程序的指令数通常为上百万条),其状态空间就已经达到了26 400。这意味着计算机程序需要在庞大高维空间中进行搜索。搜索的目标是要得到满足人类需求的输出,而人类需求涉及功能、性能甚至是心理感受等多个维度,这也使得搜索目标的约束异常复杂。以手机的设计为例,除了核心的功能和性能等参数,还涉及需要满足视觉、触觉和交互等主观感受的约束。传统人工求解方法由于搜索空间庞大同时“搜索+验证”的迭代周期太长,在求解问题时通常仅限于找到满足约束的解,而人工智能方法可以极大加速“搜索+验证”过程,从而找到满足约束的最优解。
上述科学问题的求解面临诸多挑战,主要体现在搜索效率、约束表达和验证精度上。
挑战一:如何对庞大的高维空间进行有效剪枝。对于传统的人工方法而言,由于人脑搜索能力和验证开销等限制,必须引入专家领域知识对空间进行大幅裁剪,从而在剪枝后的有限空间中进行搜索和验证。对于AI技术而言,由于没有领域知识或难以形式化表达,需要在庞大的高维空间中直接进行搜索。这种方式可以比人类专家考虑更多的潜在候选,从而找到人类专家未知的更优解。但是,由于空间过于庞大,即使是计算机程序也无法做到对整个空间的全遍历,因此通过AI技术对空间进行精确剪枝,从而在不丢失最优解的前提下将空间压缩多个数量级至关重要。
挑战二:如何准确地表达人类模糊二义甚至是不完整的需求规范。很多情况下,人类需求通常采用自然语言来进行描述,天然具有模糊二义性。同时,初始的用户需求经常具有不完整性,需要通过不断地迭代交互来细化和明确需求规范。例如,赫伯特西蒙就以舰艇设计为例说明了设计约束的复杂性,需要指挥官、作战人员、设计人员和各组件设计负责人等的不断交互迭代才能转变成为方便计算机求解的“结构良好问题”(well-structured problem)。近来热门的大语言模型由于建模了大量人类常识和经验,有望在从需求描述到问题形式化定义的转换过程中提供有效支撑。
挑战三:如何保证输出个体精确满足复杂约束。如前所述,AI for Technology要求输出的单个人造物能够精确地满足预定义的需求规范,即在单个样本上就要达到绝对正确。这与主流AI算法(如神经网络)主要强调统计意义上的精确性(对一张图片的识别错误影响不大)是矛盾的。即便是大语言模型在很多场景下提高了输出结果的精度,也无法在理论上提供精度的保证,导致在很多关键场景下仍然无法应用。因此需要通过算法理论的创新,能够在理论上保证输出精度或给出算法的理论下界,使得用户对输出结果是否满足需求规范有明确判断。
AI for Technology的应用实践:CPU芯片的全自动设计
笔者将AI for Technology的基本思想应用到了信息技术的核心物质载体——中央处理器(CPU)的设计和实现中,首次成功实现了在无人干预情况下由机器全自动设计出一款32位CPU——“启蒙1号”。与传统流程一般需要2—3年才能设计出一款工业级的CPU芯片不同,笔者团队仅在5小时内就完成了“启蒙1号”的全部前端设计,极大地提高CPU芯片的设计效率,有望变革传统的芯片设计流程。
与传统基于人工的CPU设计流程从需求规范出发,并且主要由工程师完成架构设计、逻辑设计、功能验证等流程不同,笔者团队提出的CPU设计方法本质上是以验证为中心的设计方法:在验证计划指导下从随机电路出发,由机器全自动完成包括验证、调试和修复的反复迭代直到获得满足设计需求的目标电路(图1)。其中,自动验证主要是检查结果是否满足需求并自动生成新的验证用例,自动调试是根据出错的结果搜索并定位出错的电路逻辑,自动修复则是在出错的电路逻辑基础上进一步搜索正确的电路逻辑。因此,自动调试和自动修复都可以看作是搜索的过程,与自动验证一起组成的完整流程遵循前面所介绍AI for Technology的“搜索+验证”核心流程。
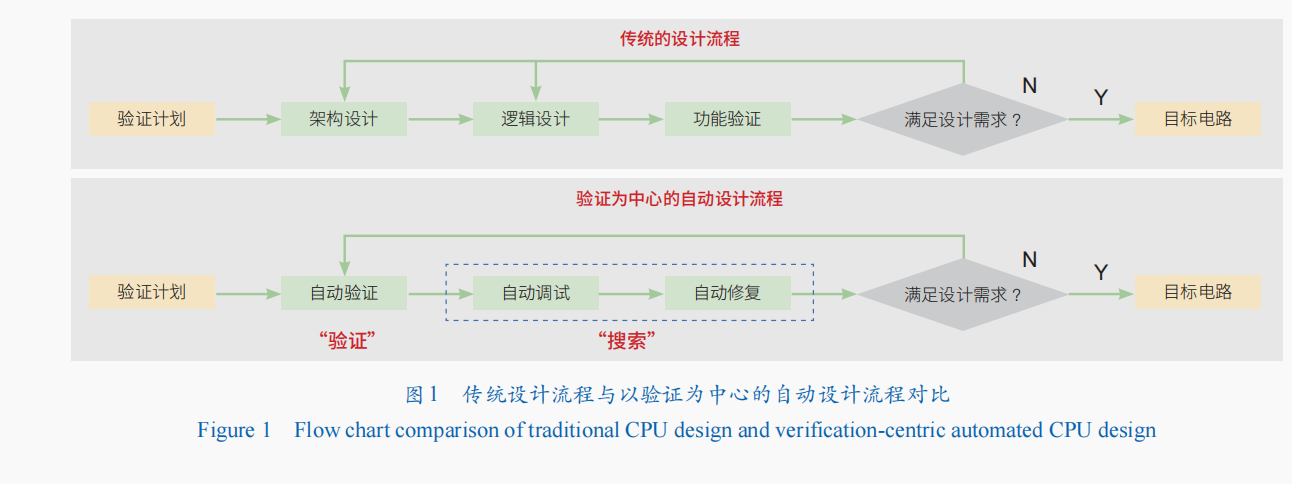
为了保证验证的精度,笔者提出了基于二元猜测图(Binary Speculation Diagram,BSD)的设计方法。BSD方法是建立在传统的二元决策图(Binary Decision Diagram,BDD)的基础上,通过将传统BDD中的确定性子图替换成BSD中通过蒙特卡洛采样来确定的猜测节点。该方法天然具有良好的可解释性和“单调性”(即算法每次对电路的修改都能够比之前的设计更接近正确的设计),从而解决前述“自动调试”和“自动修复”的问题。具体而言,首先,BDD算法的树状结构能够很快搜索确定节点所对应的逻辑函数与外部输入输出之间的关系,从而自动定位错误以解决自动调试的问题;其次,随着BDD的不断搜索展开,其所对应的逻辑函数理论上可以不断逼近原始函数,从而解决自动修复的问题。
CPU全自动设计是AI for Technology的典型应用,即通过AI技术来发明创造出CPU设计。实际上笔者发现自动设计出来的CPU不仅满足了由指令集架构(ISA)所预定义的功能需求,同时机器学习过程中甚至自主地发现了包含控制器和运算器等在内的冯诺依曼架构。对于机器而言,由于事先并没有关于冯诺依曼架构的任何预定义知识,这在一定程度上也同时呈现出了AI for Science用于“科学发现”和“结果未知”的特征。
AI for Technology的未来展望
为了让AI for Technology能够在更多的高技术领域得到深度应用,未来可以从“搜索+验证”的核心流程入手,考虑如何进一步提高搜索和验证的效率,在加速创新流程的同时具备更强的创造能力,最终期望超过人类的发明创造水平。具体可以分别从人工智能范式的交叉融合、与第三科研范式的交叉融合等方面进行探索研究。
从搜索的角度看,其核心目的是提高搜索算法本身的效率,使其能够以更快速度逼近最优解。梯度下降法在神经网络等领域取得了巨大的成功,但是很多实际问题本身并不可微或者可微近似会带来极大的精度损失,导致难以直接应用梯度下降法。这种情况下应考虑多种人工智能范式的交叉融合。例如,AlphaGo中蒙特卡洛树搜索结合了以深度学习为代表的连接主义和以强化学习为代表的行为主义。这包養标志着连接主义和行为主义已经在实际应用中呈现出了交叉融合的趋势。前面所介绍的CPU设计例子主要是基于以BDD为代表的符号主义来进行搜索。未来通过符号主义、连接主义和行为主义的深度交叉融合,有望大幅度提升搜索效率,从而在更大的搜索空间中找到更优的结果。
从验证的角度看,对输出结果包養是否满足需求规范进行判断通常要在真实环境中进行实验验证。例如,新材料的设计需要通过实际实验来对其力学特性和耐久特性等进行充分测试。这势必会造成验证的资源投入和时间开销太大。为加速验证收敛,可以借助计算机模拟来构建响应模型,通过与响应模型的交互来判断是否满足需求规范。仍以CPU设计为例,实践中无法对每种可能的处理器设计都通过实际流片来进行验证,而是通过构建准确的模拟器来判断是否满足需求。因此,未来通过与基于计算机模拟的第三科研范式进行深入融合,构建起高效且准确的响应模型,有望进一步加速验证乃至整个创新流程。
(作者:陈云霁,中国科学院计算技术研究所 中国科学院大学计算机科学与技术学院;郭崎,中国科学院计算技术研究所。《中国科学院院刊》供稿)
No Responses